
NVIDIA 刷新大數據分析基準的紀錄
前言:
RAPIDS 資料科學軟體在 DGX A100 上高速運行
將 TPCx-BB 的運算表現一舉提高了19.5倍
NVIDIA (輝達) 剛向世人展現出一舉刷新舊紀錄的堅強實力,將運行 TPCx-BB 這項大數據分析基準的效能表現提高近20倍。
NVIDIA 使用由 16 台 NVIDIA DGX A100 系統支援的 RAPIDS 開源資料科學軟體庫套件,僅花費 14.5 分鐘便完成了這項基準測試,而對比先前的紀錄,使用 CPU 系統花了 4.7 小時才完成測試。這 16 台 DGX A100 系統共有 128 個 NVIDIA A100 GPU,並且使用 NVIDIA Mellanox 網路技術。
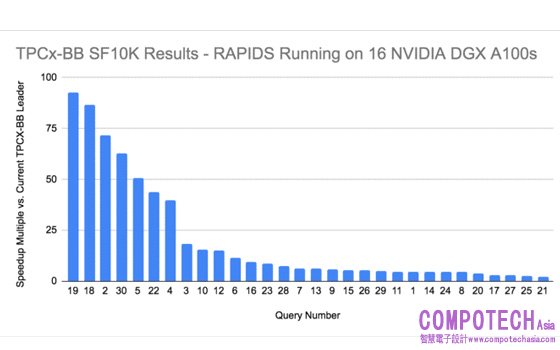
圖_TPCx-BB 基準測試結果涉及 30 個查詢項目。RAPIDS 在 16 台 DGX A100 系統上運行時,可以為每個 10TB 測試查詢提供上述的相對效能提升
所有系統忙碌運行:各項軟硬體齊頭並進,達到全速前進的結果
我們在進行分析之際,實際結果的重要性不言而喻;而在實際環境中,組織使用人工智慧 (AI) 來取得深入的見解。TPCx-BB 基準測試在進行查詢時,是使用 SQL 和機器學習來處理結構化資料,以及使用自然語言處理和非結構化資料,反映出現代資料分析工作流程中的多樣性。
我們在進行分析之際,實際結果的重要性不言而喻;而在實際環境中,組織使用人工智慧 (AI) 來取得深入的見解。TPCx-BB 基準測試在進行查詢時,是使用 SQL 和機器學習來處理結構化資料,以及使用自然語言處理和非結構化資料,反映出現代資料分析工作流程中的多樣性。
這些結果樹立出一個新的標準,而這個新標準的背後推手是透過 NVIDIA 的軟硬體商業生態體系所獲得。
在運行此一測試基準時,NVIDIA 在資料處理與機器學習方面用上了 RAPIDS、在水平擴展方面用上了 Dask,在超高速通訊方面則用上了 UCX 開源函式庫,並且全都在 DGX A100 上加速運行。
DGX A100 系統可以在單一軟體定義平台上,有效推動進行分析、AI 訓練與推論等作業。DGX A100 將 NVIDIA 最新的 Ampere 架構 NVIDIA A100 Tensor Core GPU 與 NVIDIA Mellanox 網路技術整合在一起,構成了一個易於擴展的一站式系統。
平行處理創造出無與倫比的效能表現
TPCx-BB 是一個用於企業的大數據基準,代表現實環境中的 ETL (擷取、轉換、載入) 與機器學習工作流程。該基準的三十個查詢項目包括庫存管理、價格分析、銷售分析、推薦系統、客戶區隔和觀點分析等大數據分析使用案例。
TPCx-BB 是一個用於企業的大數據基準,代表現實環境中的 ETL (擷取、轉換、載入) 與機器學習工作流程。該基準的三十個查詢項目包括庫存管理、價格分析、銷售分析、推薦系統、客戶區隔和觀點分析等大數據分析使用案例。
儘管分散式運算系統不斷穩定進步著,但在 CPU 上進行這類大數據分析工作仍會遇到瓶頸。在 DGX A100 上使用 RAPIDS 進行分析的結果,象徵著第一個在 GPU 上進行的非正式 TPCx-BB 基準,而這項測試基準過去只在 CPU 系統上運行。
在這項測試基準中,RAPIDS 軟體商業生態體系與 DGX A100 系統加快了運算、通訊、網路及儲存基礎架構的運行速度,而這種整合為大規模運行資料科學工作量奠定新的標竿。
大數據規模的高效率測試基準
在 SF10000 TPCx-BB 的規模方面,NVIDIA 的測試結果代表著分析 10TB 以上資料量的表現。
在 SF10000 TPCx-BB 的規模方面,NVIDIA 的測試結果代表著分析 10TB 以上資料量的表現。
透過這麼大的資料量進行查詢,其複雜度會迅速拉長執行時間,進而增加資料中心於空間、伺服器設備、電力、冷卻和 IT 專業技術等方面的開銷。彈性的 DGX A100 架構可以協助資料中心因應這些難題。
NVIDIA 的硬體合作夥伴即將推出全新的 NVIDIA A100 Tensor Core GPU 系統,資料科學家就會有更多選擇,在 A100 GPU 突破性運算效能的協助下,加速處理各項繁重的分析工作。
開放源碼社群通力合作,加快發展腳步
許多合作夥伴與開源團體積極參與 RAPIDS TPCx-BB 基準 這項專案。
許多合作夥伴與開源團體積極參與 RAPIDS TPCx-BB 基準 這項專案。
將一連串使用 RAPIDS DataFrame 函式庫、cuDF、RAPIDS 機器學習函式庫、cuML、CuPy、BlazingSQL 及 Dask 的 Python 腳本當成主要函式庫來進行TPCx-BB 查詢作業。在使用者定義的函數中使用 Numba 來執行自訂邏輯項目,在命名實體識別 (Named Entity Recognition) 則是使用 spaCy。
少了 RAPIDS 及更龐大的 PyData 商業生態體系,便無法達到這些成果。
欲瞭解更多關於 RAPIDS 測試基準的結果,請參閱 RAPIDS Blog。更多關於 RAPIDS 的資訊,請瀏覽 rapids.ai。






